
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- CodePipeline
- spring kafka
- entity graph
- PAGING
- Entity
- offsetdatetime
- centos7
- cd
- AWS
- Spring JPA
- topic생성
- bean
- transactionaleventlistener
- mysql
- JPA
- pgvector
- API
- QueryDSL
- git
- K8s
- producer
- Streams
- Kubernetes
- CI
- kafka
- consumer
- spring
- Kotlin
- Spring Data JPA
- ECS
Archives
- Today
- Total
Yebali
Kafka MirrorMaker2 (카프카 미러메이커2) 본문
미러메이커2
카프카 미러메이커2는 서로 다른 두 개의 카프카 클러스터 간에 토픽을 복제하는 애플리케이션이다.
'프로듀서 + 컨슈머'를 사용하여 직접 미러링 할 수 있지만,
토픽의 모든 것(메시지 키, 메시지 값, 동일한 파티션에 레코드 넣기 등)을 동일하게 복제하기는 어렵다.
커넥터로 사용할 수 있도록 설계되었기 때문에, 커넥트를 운영중이라면 미러메이커2 커넥터를 실행하여 토픽을 복제 할 수 있다.
미러메이커1..?
레거시 버전의 미러메이커이다.
복제 전 후의 파티션 정보가 달라짐, 정확히 한번 전달(exactly once delivery)를 보장하지 못하는 등의 단점이 많다.
미러메이커2를 사용하면 카프카 클러스터 단위의 활용도를 높일 수 있다.
액티브-스탠바이 클러스터 운영
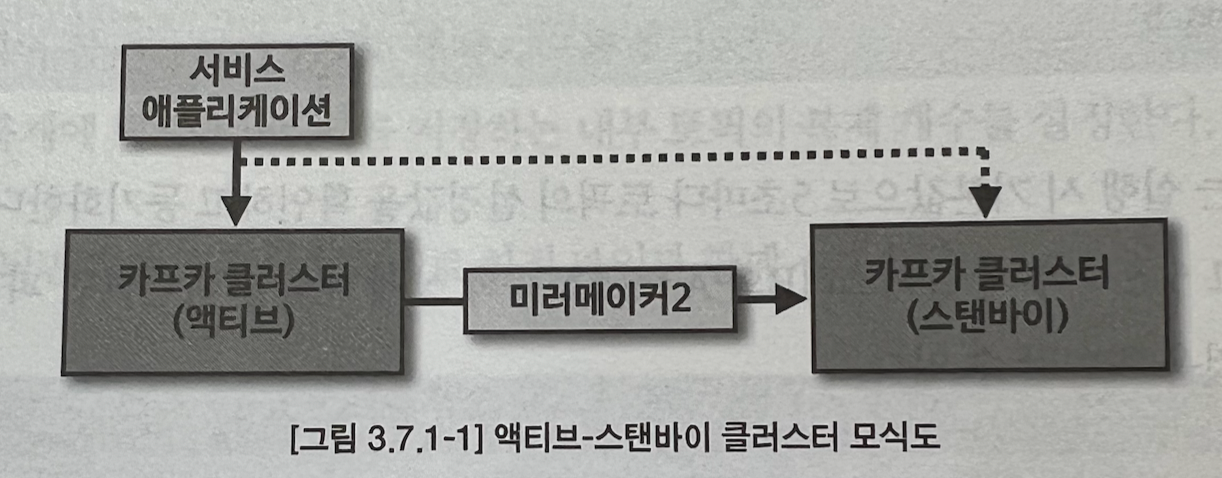
복구용으로 임시 카프카 클러스터를 하나 더 구성하여 사용하는 운영.
액티스 클러스터의 모든 토픽을 스탠바이 클러스터에 복제하여 예상치 못한 장애에 대응하는 운영 방법이다.
액티브-액티브 클러스터 운영

서비스 애플리케이션의 통신 지연을 최소화하기 위해 2개 이상의 클러스터를 두고 서로 미러링하여 운영하는 방법이다.
허브 앤 스포크 (Hub and Spoke) 클러스터 운영

한 개의 카프카 클러스터에 여러 클러스터의 데이터를 모아 사용하는 방식.
필요한 경우 양방향 토픽 복제가 쓰일 수 있다.
'Kafka' 카테고리의 다른 글
| Kafka Consumer (카프카 컨슈머) (0) | 2022.01.30 |
|---|---|
| Kafka Producer (카프카 프로듀서) (0) | 2022.01.30 |
| Kafka의 Topic과 Partition (작성 중) (0) | 2022.01.30 |
| Kafka의 ISR이란? (In-Sync-Replica) (0) | 2022.01.30 |
| Kafka 토픽 정리 정책 (0) | 2022.01.30 |
'Kafka' Related Articles
more



