
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- cd
- CI
- Kubernetes
- K8s
- transactionaleventlistener
- bean
- Entity
- Spring Data JPA
- mysql
- spring
- entity graph
- Spring JPA
- topic생성
- git
- kafka
- ECS
- mirror maker2
- Kotlin
- consumer
- JPA
- QueryDSL
- PAGING
- Streams
- centos7
- producer
- AWS
- offsetdatetime
- spring kafka
- API
- CodePipeline
- Today
- Total
Yebali
Kafka Consumer (카프카 컨슈머) 본문
컨슈머
컨슈머는 카프카에 적재된 데이터를 처리한다.
컨슈머의 고급 활용법과 옵션별 동작 방식을 알아보자
멀티 스레드 컨슈머
파티션을 여러 개 운영하는 경우 파티션의 개수와 컨슈머 개수를 동일하게 하는 것이 가장 좋다.
그렇다면 ‘1개의 프로세스 + N개의 스레드’ OR ‘N개의 프로세스 + 각 1개의 스레드’ 무엇이 더 좋을까?
-> 개발자 선택에 달렸다. 운영하는 환경을 잘 파악하고 선택하자.
멀티 스레드로 운영할 경우 하나의 스레드에서 예외가 발생하여 프로세스 자체가 종료되면 다른 스레드까지 영향을 미치기 때문에 중복, 유실 등의 문제가 발생할 수 있다. + 스레드 세이프 로직, 변수를 적용을 고려해야 한다.
멀티 스레드 운영방식은 두 가지로 나뉜다.
- 하나의 컨슈머 스레드, 데이터 처리를 담당하는 여러 개의 워커 스레드를 실행하는 전략
-> 멀티 워커 스레드 전략 - 컨슈머 인스턴스에서 poll() 메서드를 호출하는 스레드를 여러 개 띄워서 사용하는 전략
-> 컨슈머 멀티 스레드 전략
멀티 워커 스레드 전략

poll()을 통해 받은 데이터를 병렬 처리함으로써 속도의 이점을 확실히 얻는다.
그러나 몇 가지 주의사항이 있다.
- 스레드를 사용함으로써 데이터 처리가 끝나지 않아도 커밋을 하기 때문에 리밸런싱,
컨슈머 장애 시 데이터 유실이 발생할 수 있다.
→ 오토 커밋일 경우 poll() 메서드 호출 시 커밋을 할 수 있기 때문. - 레코드 처리 역전현상이 일어난다.
→ 스레드 별로 레코드 처리 속도가 다를 수 있기 때문.
카프카 컨슈머 멀티스레드 전략

하나의 파티션은 동일 컨슈머 중 최대 1개까지 할당된다. 그리고 하나의 컨슈머는 여러 파티션에 할당될 수 있다.
이런 특징을 가장 잘 살리는 방법은 1개의 애플리케이션에 구독하는 토픽의 파티션 개수만큼 컨슈머 스레드 개수를 늘려서 운영하는 것이다.
컨슈머 랙
컨슈머 랙은 토픽의 최신 오프셋(LOG-END-OFFSET)과 컨슈머 오프셋(CURRENT-OFFSET) 간의 차이이다.
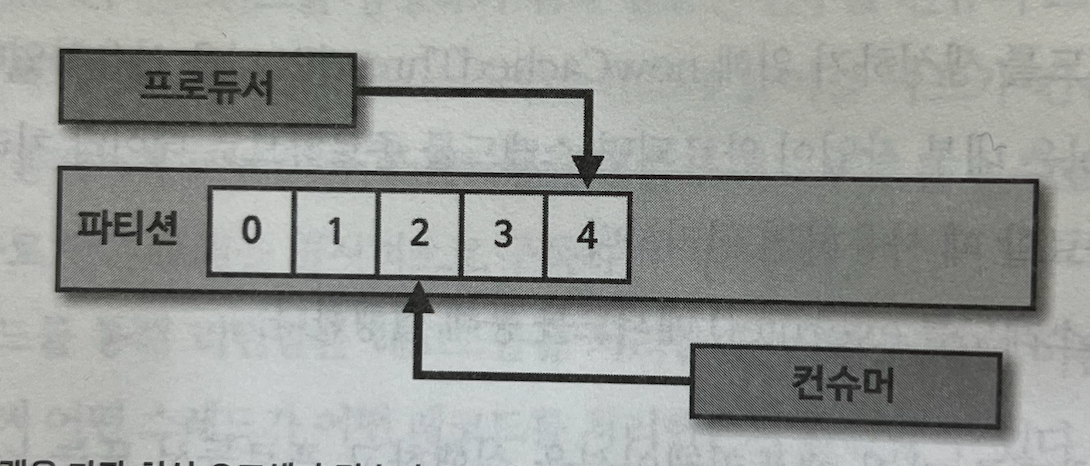
컨슈머 랙은 컨슈머 애플리케이션을 운영한다면 모니터링해야 하는 지표이다.
컨슈머 랙은 컨슈커 그룹과 토픽, 파티션별로 생성된다.
만약 하나의 토픽에 3개의 파티션이 있다면 컨슈머 그룹에는 3개의 컨슈머 랙이 존재한다.
컨슈머 랙을 확인하는 방법
- 카프카 명령어를 사용하는 방법.
- 컨슈머 애플리케이션에서metrics() 메서드를사용하는 방법.
- 외부 모니터링툴을 사용하는 방법.
카프카 명령어를 사용하여 조회
kafka-consumer-groups.sh명령어를 사용하면 컨슈머 랙을 포함하여 특정 컨슈머 그룹의 상태를 확인할 수 있다.
컨슈머 metrics() 메서드를 사용하여 조회
아래 3가지 지표를 확인할 수 있다.
- records-lag-max : 파티션들의 컨슈머 랙 중 가장 큰 값
- records-lag : 특정 파티션에 대한 컨슈머 랙
- records-lag-avg : 파티션들의 컨슈머 랙 평균값
하지만 이 방법은 문제점이 있다.
- 컨슈머가 정상적으로 동작해야만 해당 메서드가 호출된다.
- 모든 컨슈머 애플리케이션에 동일한 모니터링 코드를 작성해야 한다.
- 모니터링 코드를 추가할 수 없는 서드 파티 애플리케이션은 모니터링할 수 없다.
외부 모니터링 툴을 사용하여 조회
데이터 독(Data dog), 컨플루언트 컨트롤 센터와 같은 툴을 사용하면 운영에 필요한 다양한 지표를 모니터링할 수 있다.
'Kafka' 카테고리의 다른 글
| Kafka 설치하기 (feat. EC2) (0) | 2022.01.31 |
|---|---|
| Spring Kafka (스프링 카프카) (0) | 2022.01.30 |
| Kafka Producer (카프카 프로듀서) (0) | 2022.01.30 |
| Kafka MirrorMaker2 (카프카 미러메이커2) (0) | 2022.01.30 |
| Kafka의 Topic과 Partition (작성 중) (0) | 2022.01.30 |



