
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- API
- AWS
- kafka
- spring
- mirror maker2
- Kubernetes
- mysql
- Kotlin
- QueryDSL
- offsetdatetime
- CodePipeline
- JPA
- CI
- producer
- Entity
- Streams
- transactionaleventlistener
- entity graph
- topic생성
- consumer
- ECS
- git
- K8s
- centos7
- cd
- bean
- PAGING
- spring kafka
- Spring JPA
- Spring Data JPA
- Today
- Total
Yebali
Spring Collection 조회 성능 비교 본문
Spring을 사용하다 보면 @OneToMany로 매핑되어 있는 Entity들을 조회하기 위해 이러저러한 방법을 지원한다.
가장 흔하게 생각할 수 있는 방법으로는 Lazy Loading, fetch join, entity graph가 있다.
테스트 환경
Entity는 Team, Member, Card가 있고 각각 1:N(OneToMany) 관계로 매핑되어 있다.
@Entity
class Team(
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
val id: Long = 0,
var name: String,
@OneToMany(mappedBy = "team", cascade = [CascadeType.PERSIST, CascadeType.REMOVE])
val members: MutableList<Member> = mutableListOf()
)
@Entity
class Member(
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
val id: Long = 0,
var name: String,
@ManyToOne
@JoinColumn(name = "team_id")
var team: Team? = null,
@OneToMany(mappedBy = "member", cascade = [CascadeType.PERSIST])
val cards: MutableSet<Card> = mutableSetOf()
)
@Entity
class Card(
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
val id: Long = 0,
val name: String,
@ManyToOne
@JoinColumn(name = "member_id")
var member: Member? = null
)테스트를 위한 데이터는 20개의 Team, 각 Team 마다 100명의 Member,
각 Member는 50개의 Card를 가지고 있도록 넣어주었다.
Spring Data Jpa를 사용하여 테스트 데이터를 세팅하면 속도가 너무 느려 jdbcTemplate를 사용하였다.
@BeforeEach
fun init() {
val teamCount = 20
val memberCountPerTeam = 100
val cardCountPerMember = 50
val teamsToInsert = (1..teamCount).map { Team(name = "team-$it") }
jdbcTemplate.batchUpdate(
"""insert into team(name) values (?)""",
object : BatchPreparedStatementSetter {
override fun setValues(ps: PreparedStatement, i: Int) {
ps.setString(1, teamsToInsert[i].name)
}
override fun getBatchSize() = teamCount
}
)
val teams = teamRepository.findAll()
val memberToInsert = teams.flatMap { team ->
(1..memberCountPerTeam).map {
Member(name = "member-${team.id}-$it", team = team)
}
}
jdbcTemplate.batchUpdate(
"""insert into member(name, team_id) values (?, ?)""",
object : BatchPreparedStatementSetter {
override fun setValues(ps: PreparedStatement, i: Int) {
ps.setString(1, memberToInsert[i].name)
ps.setLong(2, memberToInsert[i].team!!.id)
}
override fun getBatchSize() = teamCount * memberCountPerTeam
}
)
val members = memberRepository.findAll()
val cardToInsert = members.flatMap { member ->
(1..cardCountPerMember).map { Card(name = "card-${member.id}-$it", member = member) }
}
jdbcTemplate.batchUpdate(
"""insert into card(name, member_id) values (?, ?)""",
object : BatchPreparedStatementSetter {
override fun setValues(ps: PreparedStatement, i: Int) {
ps.setString(1, cardToInsert[i].name)
ps.setLong(2, cardToInsert[i].member!!.id)
}
override fun getBatchSize() = teamCount * memberCountPerTeam * cardCountPerMember
}
)
}
Lazy Loading
Spring Transaction 내에서 proxy로 존재하는 Collection 쪽 데이터가 조회될 때 DB에서 조회하는 방법이다.
batch_size는 20으로 설정하였다.
@Test
fun lazy_loading() {
val measuredTime = measureTimeMillis {
val teams = teamRepository.findAll()
teams.forEach { team ->
team.members.forEach { member ->
member.cards.forEach { card ->
card.name
}
}
}
}
println("measuredTime = $measuredTime ms")
}card의 'name'프로퍼티를 조회 하기위한 많은 쿼리가 발생 1 + 2 + 200개의 쿼리가 발생했고
약 1565ms의 시간이 걸렸다.
Hibernate: select team0_.id as id1_2_, team0_.name as name2_2_ from team team0_
Hibernate: select members0_.team_id as team_id3_1_1_, members0_.id as id1_1_1_, members0_.id as id1_1_0_, members0_.name as name2_1_0_, members0_.team_id as team_id3_1_0_ from member members0_ where members0_.team_id in (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
Hibernate: select cards0_.member_id as member_i3_0_1_, cards0_.id as id1_0_1_, cards0_.id as id1_0_0_, cards0_.member_id as member_i3_0_0_, cards0_.name as name2_0_0_ from card cards0_ where cards0_.member_id in (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
Hibernate: select cards0_.member_id as member_i3_0_1_, cards0_.id as id1_0_1_, cards0_.id as id1_0_0_, cards0_.member_id as member_i3_0_0_, cards0_.name as name2_0_0_ from card cards0_ where cards0_.member_id in (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
Hibernate: select cards0_.member_id as member_i3_0_1_, cards0_.id as id1_0_1_, cards0_.id as id1_0_0_, cards0_.member_id as member_i3_0_0_, cards0_.name as name2_0_0_ from card cards0_ where cards0_.member_id in (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
Hibernate: select cards0_.member_id as member_i3_0_1_, cards0_.id as id1_0_1_, cards0_.id as id1_0_0_, cards0_.member_id as member_i3_0_0_, cards0_.name as name2_0_0_ from card cards0_ where cards0_.member_id in (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
.
.
.
measuredTime = 1565 ms쿼리가 많이 발생되어 다소 많은 시간이 걸리지만 조회 시 중복되는 데이터가 없기 때문에 메모리는 효율적으로 사용한다.
Fetch Join
조회 시, 매핑되어있는 데이터를 한번에 Join 하여 조회하는 방법이다.
Inner Join과 Left Join을 모두 실험했다.
OneToMany 쪽에 Join 하기 때문에 데이터 중복을 방지하기 위해 'Distinct()'를 사용했고
실제 distinct query는 성능에 좋지 않기 때문에 QueryHints를 사용했다.
override fun findAllWithInnerJoin(): List<Team> {
return jpaQueryFactory
.selectDistinct(team)
.from(team)
.innerJoin(team.members, member).fetchJoin()
.innerJoin(member.cards, card).fetchJoin()
.setHint(QueryHints.PASS_DISTINCT_THROUGH, false)
.fetch()
}
override fun findAllWithLeftJoin(): List<Team> {
return jpaQueryFactory
.selectDistinct(team)
.from(team)
.leftJoin(team.members, member).fetchJoin()
.leftJoin(member.cards, card).fetchJoin()
.setHint(QueryHints.PASS_DISTINCT_THROUGH, false)
.fetch()
}테스트 코드 자체는 거의 동일하다.
@Test
fun inner_join_fetch() {
val measuredTime = measureTimeMillis {
val teams = teamRepository.findAllWithInnerJoin()
teams.forEach { team ->
team.members.forEach { member ->
member.cards.forEach { card ->
card.name
}
}
}
}
println("measuredTime = $measuredTime ms")
}
@Test
fun left_join_fetch() {
val measuredTime = measureTimeMillis {
val teams = teamRepository.findAllWithLeftJoin()
teams.forEach { team ->
team.members.forEach { member ->
member.cards.forEach { card ->
card.name
}
}
}
}
println("measuredTime = $measuredTime ms")
}두 테스트 모두 Query는 하나만 발생하며 약 500 ms의 시간이 걸렸다.
// Inner Join
Hibernate:
select
team0_.id as id1_2_0_,
members1_.id as id1_1_1_,
cards2_.id as id1_0_2_,
team0_.name as name2_2_0_,
members1_.name as name2_1_1_,
members1_.team_id as team_id3_1_1_,
members1_.team_id as team_id3_1_0__,
members1_.id as id1_1_0__,
cards2_.member_id as member_i3_0_2_,
cards2_.name as name2_0_2_,
cards2_.member_id as member_i3_0_1__,
cards2_.id as id1_0_1__
from
team team0_
inner join member members1_ on team0_.id = members1_.team_id
inner join card cards2_ on members1_.id = cards2_.member_id
measuredTime = 571 ms
// Left Join
Hibernate:
select
team0_.id as id1_2_0_,
members1_.id as id1_1_1_,
cards2_.id as id1_0_2_,
team0_.name as name2_2_0_,
members1_.name as name2_1_1_,
members1_.team_id as team_id3_1_1_,
members1_.team_id as team_id3_1_0__,
members1_.id as id1_1_0__,
cards2_.member_id as member_i3_0_2_,
cards2_.name as name2_0_2_,
cards2_.member_id as member_i3_0_1__,
cards2_.id as id1_0_1__
from
team team0_
left outer join member members1_ on team0_.id = members1_.team_id
left outer join card cards2_ on members1_.id = cards2_.member_id
measuredTime = 538 ms
Entity Graph
Entity Graph는 Entity 조회 시점에 연관된 Entity들을 함께 조회하는 기능이다.
interface TeamRepository : CustomTeamRepository, JpaRepository<Team, Long> {
@EntityGraph(attributePaths = ["members", "members.cards"])
override fun findAll(): List<Team>
}역시 테스트 코드는 거의 동일하다.
@Test
fun entity_graph() {
val measuredTime = measureTimeMillis {
val teams = teamRepository.findAll()
teams.forEach { team ->
team.members.forEach { member ->
member.cards.forEach { card ->
card.name
}
}
}
}
println("measuredTime = $measuredTime ms")
}Left Join과 동일한 Query가 발생했지만 테스트에 걸린 시간은 342ms였다.
Hibernate:
select
team0_.id as id1_2_0_,
members1_.id as id1_1_1_,
cards2_.id as id1_0_2_,
team0_.name as name2_2_0_,
members1_.name as name2_1_1_,
members1_.team_id as team_id3_1_1_,
members1_.team_id as team_id3_1_0__,
members1_.id as id1_1_0__,
cards2_.member_id as member_i3_0_2_,
cards2_.name as name2_0_2_,
cards2_.member_id as member_i3_0_1__,
cards2_.id as id1_0_1__
from
team team0_
left outer join member members1_ on team0_.id = members1_.team_id
left outer join card cards2_ on members1_.id = cards2_.member_id
measuredTime = 342 msFetch Join, Entity Graph의 공통적인 문제
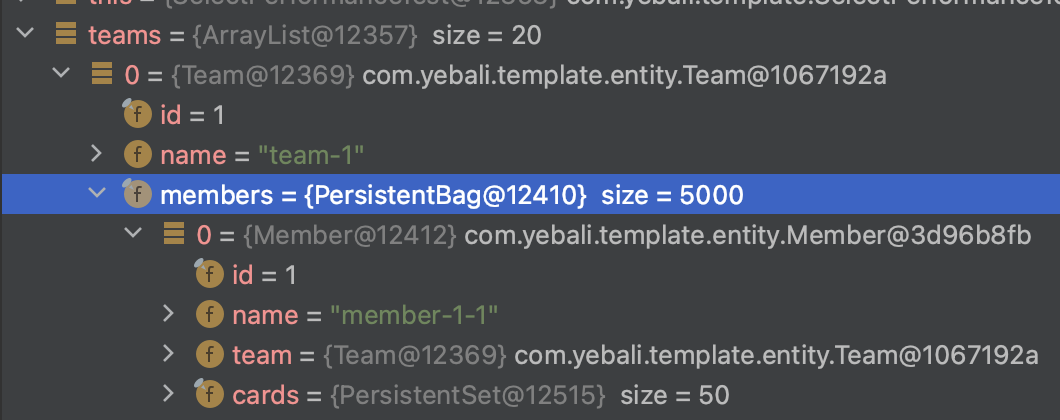
fetch Join과 Entity Graph는 조회했을 때 Member Entity가 중복하는 문제가 발생했다.
Member와 Card의 카테시안 곱만큼 데이터가 생기기 때문인데 이런 건 분명히 메모리를 낭비하는 것으로 생각된다.
'Spring' 카테고리의 다른 글
| Spring Boot의 Auto Configuration (0) | 2023.10.26 |
|---|---|
| WebSocket 구현하기 feat.Spring (0) | 2023.02.10 |
| [Spring] 테스트에서 Static 메소드 Mocking하기 (0) | 2022.09.24 |
| Spring의 Filter와 Interceptor (0) | 2022.01.23 |
| Join의 종류와 QueryDsl (0) | 2021.11.01 |



