Kafka Connect (카프카 커넥트)
카프카 커넥트란?
카프카 오픈소스에 포함된 툴 중 하나로 데이터 파이프라인 생성 시 반복 작업을 줄이고 효율적인 전송을 이루기 위한 애플리케이션이다.
특정한 작업 형태를 템플릿으로 만들어놓은 커넥터를 실행하면, 프로듀서/컨슈머 애플리케이션 개발/배포/운영 작업의 반복을 줄일 수 있다.
커넥터는 각 커넥터가 가진 고유한 설정값을 받아서 데이터를 처리한다.
(ex, 파일의 데이터를 토픽으로 보내는 커넥터는 파일이존재하는 디렉토리 위치, 파일 이름을 설정해야 한다.)
커넥터의 종류
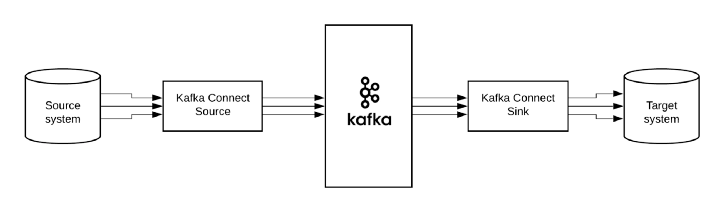
- 소스 커넥터 : 데이터를 토픽으로 가지고 오는 프로듀서 역할을 하는 커넥터
- 싱크 커넥터 : 데이터를 다른 애플리케이션으로 보내는 컨슈머 역할을 하는 커넥터
Mysql → Kafka / Kafka → Mysql 할 때, JDBC 커넥터를 사용하여 파이프라인을 생성할 수 있다.
커넥터들은 직접 만들 필요 없이 jar파일을 다운로드 하여 사용할수 있다.
커넥터 사용법
사용자가 커넥터 생성 명령을 내리면 커넥트는 내부에 커넥터와 태스크를 생성한다.
커넥터는 태스크들을 관리하고, 태스크는 실질적인 데이터 처리를 한다.
커넥터를 이용해 파이프라인을 생성할 때, 컨버터와 트랜스폼 기능을 옵션으로 추가할 수 있다.
- 컨버터 : 데이터 처리를 하기 전 스키마를 변경하기 위한 기능.
JsonConverter, StringConverter, ByteArrayConverter를 지원하고 필요하다면 커스텀할 수 있다. - 트랜스폼 : 데이터 처리 시 각 메시지 단위로 데이터를 간단하게 변환하기 위한 기능.
Json의 경우 특정 키를 삭제하거나 추가할 수 있다.
커넥트 실행 모드
단일 모드 커넥트
단일 모드 커넥트는 1개 프로세스만 실행된다. (고가용성 X)
개발 환경이나 중요도가 낮은 파이프라인을 운용할 때 사용한다.
분산 모드 커넥트
2개 이상의 서버에서 클러스터 형태로 운영하는 형태이다.
다른 커넥트에 이슈가 발생해도 남은 커넥트가 파이프라인을 지속적으로 처리해준다.
분산 모드 커넥트를 사용 시, group.id가 동일한 커넥트들은 같은 그룹으로 인식한다.
이를 통해 커넥트 중 한 대에 이슈가 발생하더라도 나머지 커넥트가 커넥터를 안전하게 실행할 수 있다.
REST API를 사용하면 실행 중인 커넥트의 플러그인 종류, 태스크 상태 등을 조회할 수 있다.
connector 목록 조회
curl -X GET "http://localhost:8083/connectors/"
connector 상세 정보 조회
curl -X GET "http://localhost:8083/connectors?expand=status&expand=info"
등 등 여러 가지 API를 제공한다.
소스 커넥터
소스 커넥터를 직접 개발해야 하는 경우 카프카 커넥트 라이브러리에서 제공하는 SourceConnector와 SourceTask클래스를 사용하여 직접 구현하면 된다.
직접 구현할 때에는 SourceConnector는 아래 6개의 메서드를 구현해야 한다.
public class TestSourceConnector extends SourceConnector {
@Override
public String version() {
// 커넥터의 버전을 반환
}
@Override
public void start(Map<String, String> props) {
// 사용자가 입력한 설정값을 초기화 하는 메서드
}
@Override
public Class<? extends Task> taskClass() {
// 커넥터가 사용 할 태스크 클래스를 지정
}
@Override
public List<Map<String, String>> taskConfigs(int maxTasks) {
// 태스크 개수가 2개 이상인 경우 태스크마다 다른 옵션을 설정할 때 사용
}
@Override
public ConfigDef config() {
// 커넥터가 사용할 설정값에 대한 정보를 받는다.
}
@Override
public void stop() {
// 커넥터가 종료될 때 필요한 로직을 작성
}
}
SourceTask는 아래 4개 메서드를 구현해야 한다.
public class TestSourceTask extends SourceTask {
@Override
public String version() {
// 태스크의 버전을 반환
}
@Override
public void start(Map<String, String> props) {
// 태스크가 시작할 때 필요한 로직을 작성
}
@Override
public List<SourceRecord> poll() {
// 소스 애플리케이션에서 데이터를 읽어오는 로직을 작성
}
@Override
public void stop() {
// 태스크가 종료될 때 필요한 로직을 작성
}
}싱크 커넥터
싱크 커넥터 역시 직접 구현할 수 있으며 직접 개발해야 하는 경우 카프카 커넥트 라이브러리에서 제공하는 SinkConnector와 SinkTask클래스를 사용하여 직접 구현하면 된다.
직접 구현할 때에는 SinkConnector는 아래 6개의 메서드를구현해야 한다.
public class TestSinkConnector extends SinkConnector {
@Override
public String version() {
// 커넥터의 버전을 반환
}
@Override
public void start(Map<String, String> props) {
// 사용자가 입력한 설정값을 초기화 하는 메서드
}
@Override
public Class<? extends Task> taskClass() {
// 커넥터가 사용 할 태스크 클래스를 지정
}
@Override
public List<Map<String, String>> taskConfigs(int maxTasks) {
// 태스크 개수가 2개 이상인 경우 태스크마다 다른 옵션을 설정할 때 사용
}
@Override
public ConfigDef config() {
// 커넥터가 사용할 설정값에 대한 정보를 받는다.
}
@Override
public void stop() {
// 커넥터가 종료될 때 필요한 로직을 작성
}
}
SinkTask는 아래 5개 메서드를 구현해야 한다.
public class TestSinkTask extends SinkTask {
@Override
public String version() {
// 태스크의 버전을 반환
}
@Override
public void start(Map<String, String> props) {
// 태스크가 시작할 때 필요한 로직을 작성
}
@Override
public void put(Collection<SinkRecord> records) {
// 저장할 데이터를 토픽에서 주기적으로 가져오는 메서드
}
@Override
public void flush(Map<TopicPartition, OffsetAndMetadata> offsets) {
// put()메서드를 통해 가져온 데이터를 일정 주기로 애플리케이션에 저장하는 로직
}
@Override
public void stop() {
// 태스크가 종료될 때 필요한 로직을 작성
}
}