
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Spring JPA
- Entity
- git
- mysql
- AWS
- entity graph
- producer
- cd
- Streams
- kafka
- topic생성
- consumer
- K8s
- ECS
- spring
- CodePipeline
- transactionaleventlistener
- offsetdatetime
- mirror maker2
- Kotlin
- API
- JPA
- PAGING
- Spring Data JPA
- QueryDSL
- spring kafka
- centos7
- Kubernetes
- bean
- CI
- Today
- Total
Yebali
백엔드 면접 질문 본문
공용
객체 지향 프로그래밍이란?
데이터들을 '상태'와 '행위'를 가진 객체로 만들고, 객체들 간의 상호작용을 통해 로직을 구현하는 프로그래밍 기법.
추상화란?
공통 속성이나 기능을 묶어 이름을 붙이는 것.
객체 지향 관점에서는 클래스나 인터페이를 정의하는 것이 추상화 과정.
다형성이란?
다형성이란 하나의 객체가 여러 가지 타입을 가질 수 있는 것.
객체 지향에서 부모 클래스의 참조 변수로 자식 클래스의 인스턴스를 할당할 수 있는 것.
open class Parent()
class Child: Parent()
fun main(args: Array<String>) {
val p: Parent = Parent()
val c: Child = Child()
// 자식 클래스의 인스턴스가 부모 클래스의 참조 변수에 할당될 수 있다.
val p2: Parent = Child()
}
제네릭이란?
클래스 내부에서 사용할 데이터의 타입을 외부에서 지정하는 기법.
컴파일 타임에 타입이 결정되기 때문에 에러를 방지할 수 있으며, 코드 재사용성을 높일 수 있다.
쿠키와 세션 그리고 토큰이란?
HTTP은 Connectionsless/Stateless한 특성을 가지기 때문에 서버는 클라이언트가 누구인지 매번 확인해야 한다.
이때 클라이언트를 확인하기 위해 세션과 쿠키 또는 토큰을 사용한다.
- 쿠키: 클라이언트 PC에 저장되는 작은 key-value 데이터 파일.
사용자 관련 정보를 클라이언트 PC에 저장하는 방식을 의미하기도 한다. - 세션: 클라이언트의 민감한 정보를 서버에 저장하여 사용자의 상태를 관리하는 기술.
- 토큰: 서버가 클라이언트가 인증되면 '토큰'을 발급하고 클라이언트는 요청할 때마다 발급받은 토큰을 요청과 함께 보낸다.
서버는 요청을 받았을 때 토큰을 기반으로 클라이언트를 판단한다.
동시성과 병렬성의 차이
동시성은 하나의 프로세스에서 여러 스레드가 번갈아가며 마치 동시에 여러 작업이 처리되는 것처럼 동작하는 것.
병렬성은 여러 개의 프로세스가 동시에 여러 개의 작업을 처리하는 것.
비동기와 Non-blocking
비동기
비동기는 요청한 작업의 완료 여부와 상관없이 다음 작업을 진행하는 것이다.
요청한 작업이 완료되었을 때 작업 결과는 Callback을 통해 처리된다.
그렇기 때문에 여러 개의 비동기 메서드를 호출한 경우 요청한 순서대로 처리되지 않을 수 있다.

Non-blocking
Non-blocking은 요청받은 작업이 완료되지 않아도 제어권을 반환하여 다른 작업의 처리를 중단(Block)하지 않는 것을 말한다.

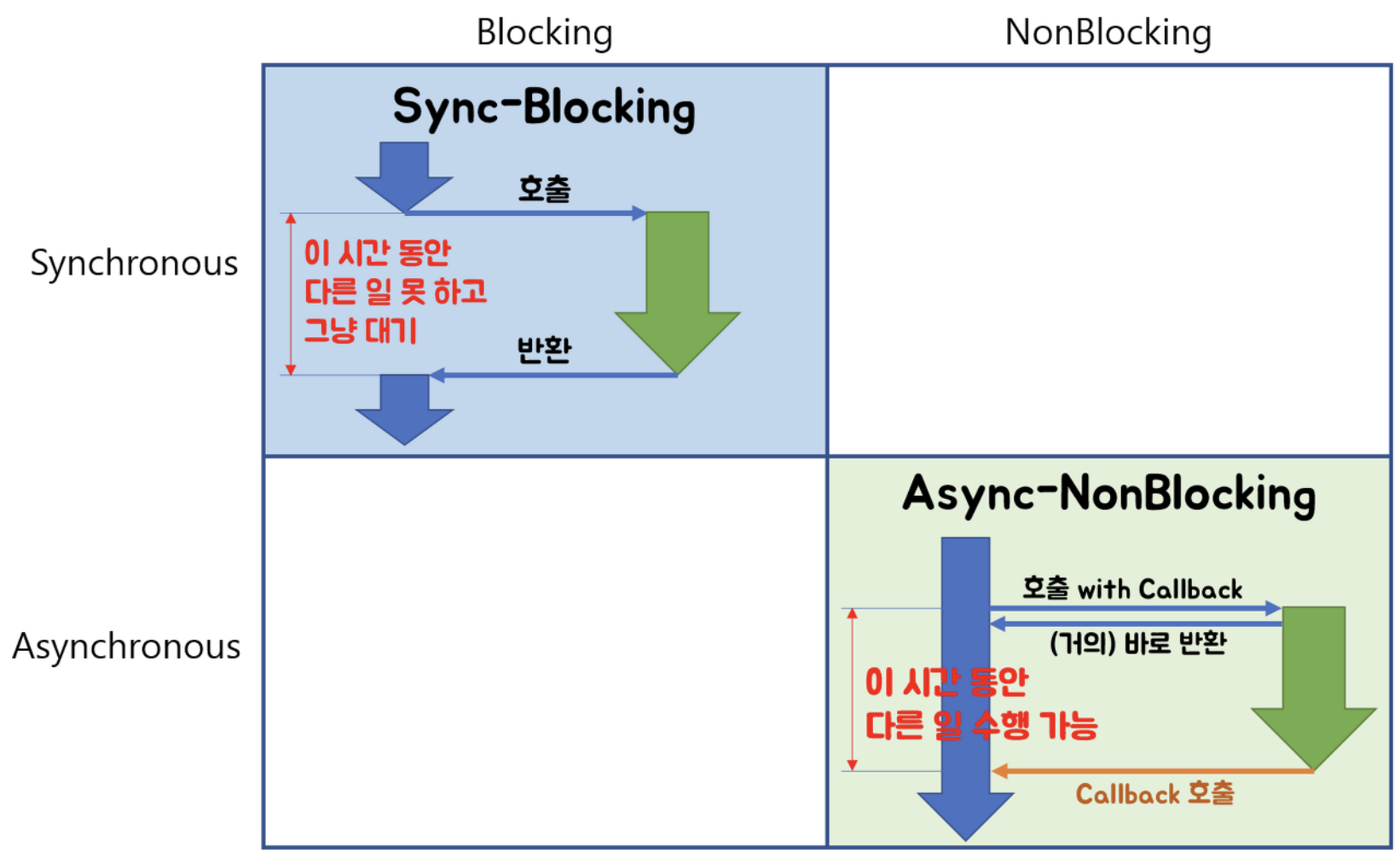
참조: https://homoefficio.github.io/2017/02/19/Blocking-NonBlocking-Synchronous-Asynchronous/
Connection timeout과 Read timeout의 차이
- Connection timeout: 클라이언트가 제한된 시간 내에 서버에 접근 자체를 하지 못함.
- Read timeout: 클라이언트가 서버에 접속했으나 제한된 시간 내에 응답받지 못해 클라이언트가 접속을 종료함.
컴파일러와 인터프리터의 차이
우리가 작성한 코드는 컴퓨터에서 실행되기 위해 기계어로 번역된다. 이때 기계어로 번역하는 방식에는 컴파일러와 인터프리터가 있다.
컴파일러는 코드 전체를 스캔하고 기계어로 번역한다. 컴파일 과정에서 오브젝트 코드(Object Code)를 만들고 오브젝트 코드를 다시 하나의 실행 파일로 만드는 링킹(Linking) 작업을 하기 때문에 일반적으로 인터프리터보다 메모리를 많이 사용한다.
하지만 모든 코드를 기계어로 번역했기 때문에 인터프리터보다 실행 속도가 빠르고
프로그램 실행 전 컴파일과정에서 여러 가지 오류를 잡아줄 수 있다는 장점이 있다.
인터프리터는 프로그램 실행 시 한 문장씩 기계어로 번역한다. 그러다 보니 컴파일러보다 실행 속도가 느리고 실행 도중에야 오류를 알 수 있다.
하지만 오브젝트 코드(Object Code)를 만들고 링킹(Linking)하는 과정이 없기 때문에 메모리 효율이 좋다.
네트워크
HTTP와 HTTPS의 차이점
HTTP(HyperText Transfer Protocol)는 평문 전송 프로토콜로 3자에 의해 정보가 쉽게 탈취될 수 있다.
HTTPS(HTTP orver Secure Socket Layer)는 HTTP 통신의 보안을 강화하기 위해 암호화 과정을 추가한 것이다.
SSL(Secure Socket Layer)을 통해 데이터를 암호화한다.
SSL은 TCP와 HTTP 사이에 위치하기 때문에 TCP <-> SSL <-> HTTP의 순서로 통신한다.
SSL은 TLS(Transport Layer Security)이라고도 불린다.
HTTP와 WebSocket의 차이점
WebSocket과 HTTP 프로토콜 모두 OSI 7 layer에 위치하고 4 layer(TCP)에 의존한다.
WebSocket은 80, 443번 포트에서 동작하게 설계되어 HTTP와 호환된다. 하지만 동일하지 않다.
첫 번째 차이는 프로토콜이다. WebSocket을 연결하기 위한 Handshake과정에서는 HTTP를 사용하지만
WebSocket 통신에서는 HTTP가 아닌 독자적인 프로토콜(ws://)을 사용한다.
두 번째 차이는 WebSocket은 전이중 통신이지만 HTTP는 단방향 통신이다.
HTTP는 매 요청마다 TCP 연결을 맺고 '클라이언트 -> 서버' 또는 '서버 -> 클라이언트'의 방향으로 데이터가 전달된다.
하지만 WebSocket은 한번 맺은 TCP 연결로 '클라이언트 <-> 서버' 간의 양방향 통신이 가능하다.
OSI 7 계층과 TCP/IP 4 계층
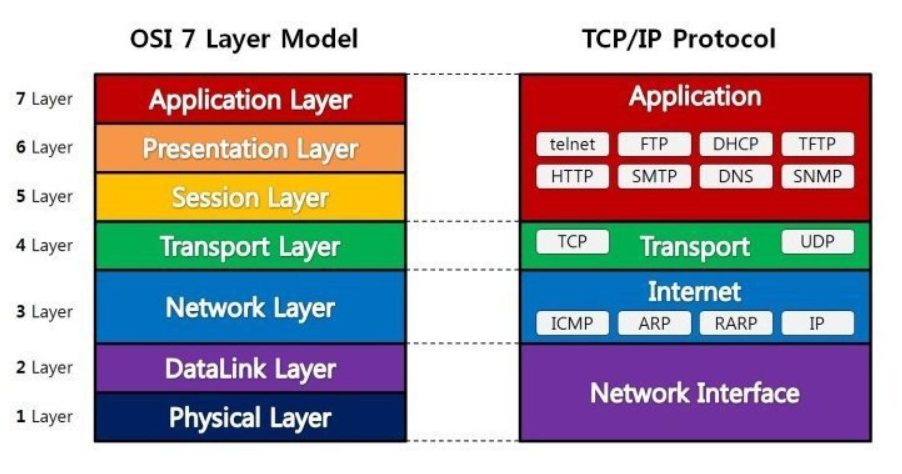
OSI 7 계층은 네트워크에서 통신이 일어나는 과정을 7단계로 나눈 것이다.
TCP/IP 4 계층은 TCP/IP 프로토콜 통신 과정에 초점을 맞추어 OSI 7 계층을 단순화시킨 계층을 의미한다.
Load Balancing 이란?
리소스(서버, DB 등) 풀 전체에 트래픽을 균등하게 배분하는 것을 말한다.
우선순위를 두지 않고 균등하게 배분하는 Round Robin방식, IP 해시 값을 기반으로 배분하는 방식 등이 있다.
TCP의 3-way handshake와 4-way handshake
3-way handshake
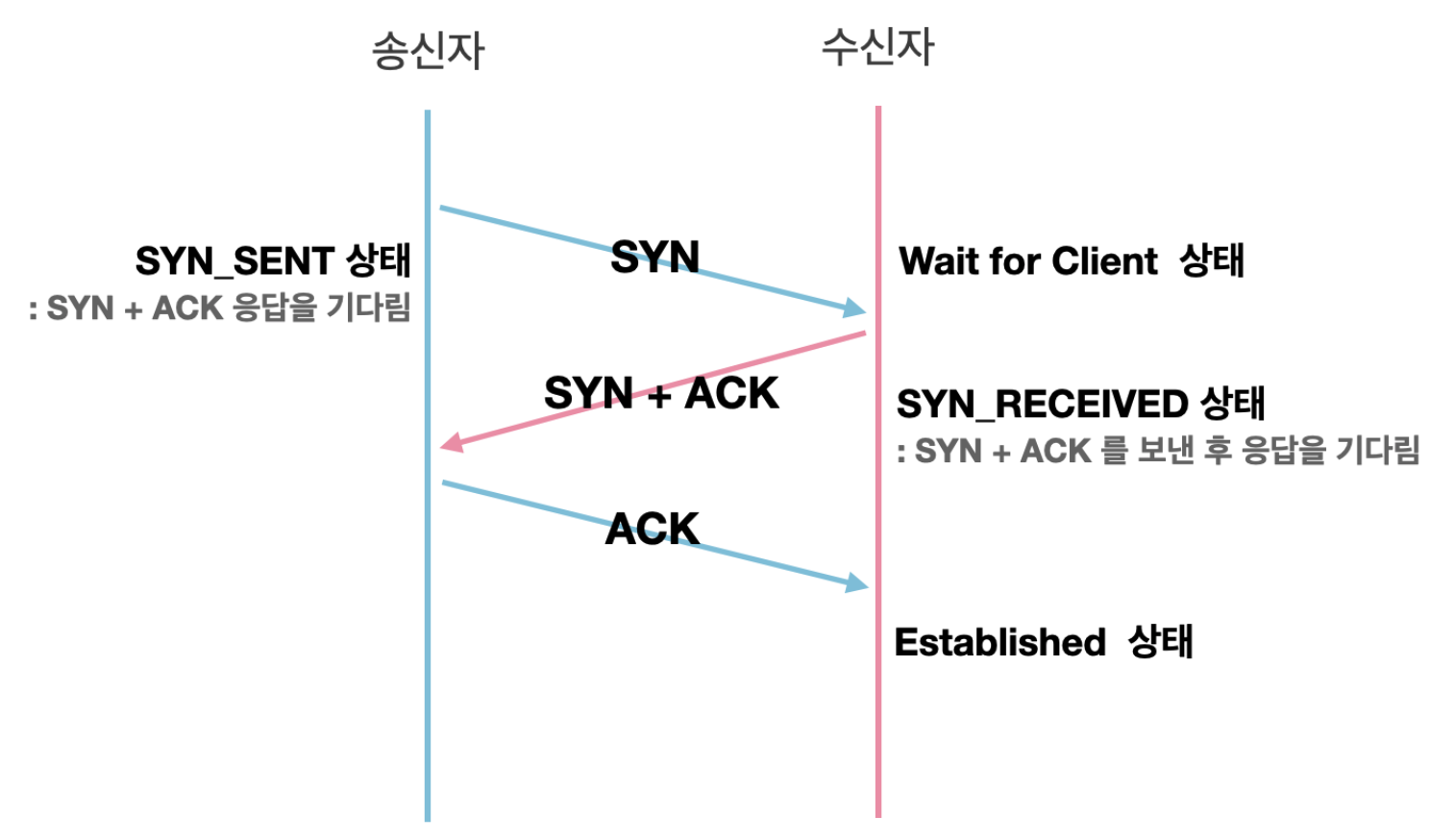
3-way handshake는 TCP 연결을 맺는 과정이다.
4-way handshake
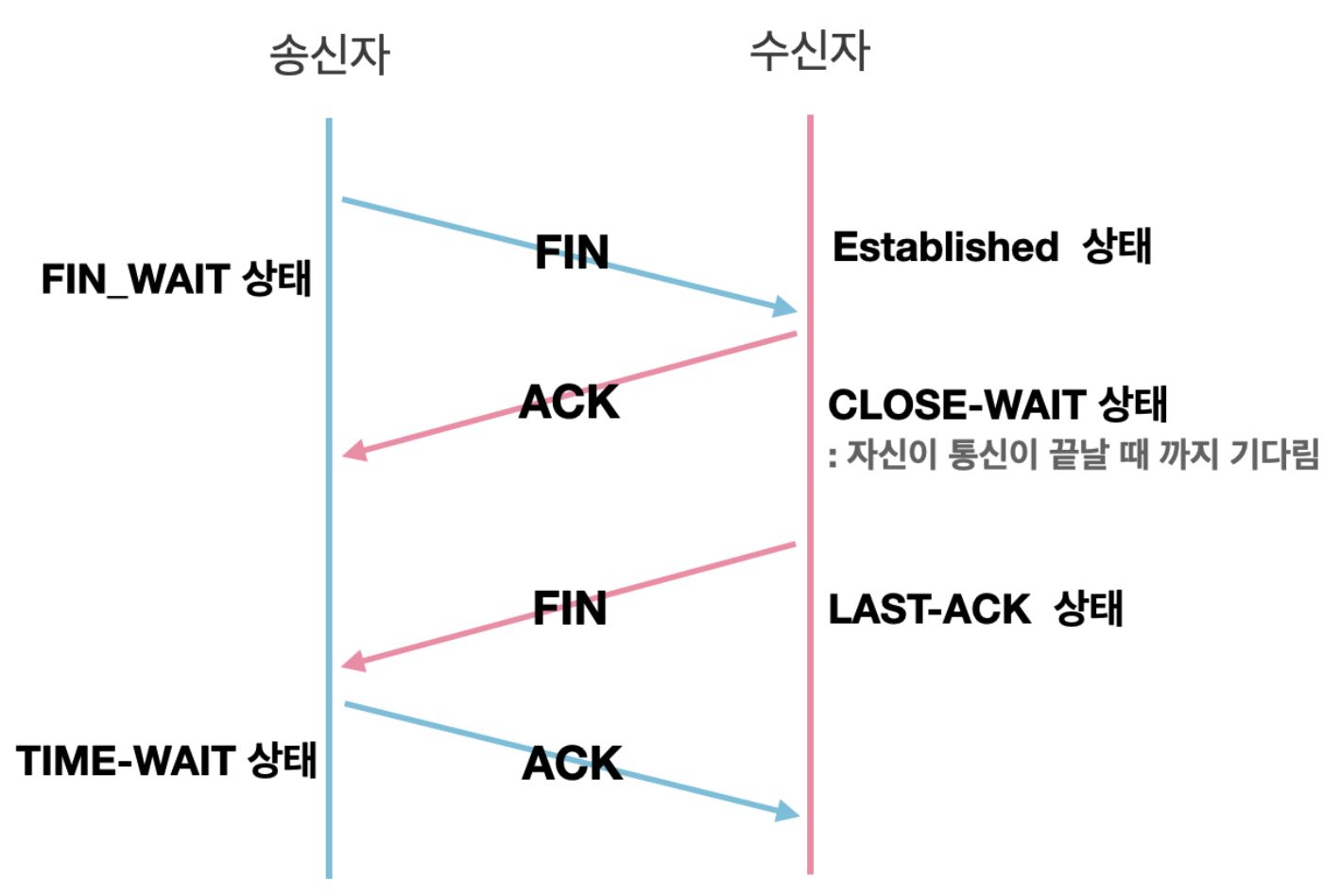
4-way handshake는 TCP 연결을 해제하는 과정이다.
운영체제
프로세스와 스레드의 차이
프로세스는 실행 중인 프로그램을 말한다.
프로세스마다 Code, Data, Heap, Stack 등의 메모리 영역을 독립적으로 할당받는다.
스레드는 프로세스 내에서 코드(명령)가 실행되는 흐름의 단위이다.
Stack을 제외한 Code, Date, Heap 등의 메모리 영역을 공유한다.
멀티 프로세싱과 멀티 스레딩의 차이
멀티 프로세싱은 다수의 프로세스가 협력하여 작업을 처리하는 것을 말한다.
하나의 프로세스에 문제가 생겨도 다른 프로세스가 영향을 받지 않는 장점이 있지만, 멀티 스레딩보다 많은 자원을 소모한다
멀티 스레딩은 하나의 프로세스가 여러 개의 스레드를 만들어 작업을 처리하는 것을 말한다
상대적으로 적은 자원을 소모하고 Context Switching이 빠르다는 장점이 있지만,
하나의 스레드에 문제가 생기면 다른 스레드에게 영향을 미치는 단점이 있다.
교착상태(Dead Lock)이란?
둘 이상의 프로세스가 자원을 점유한 상태에서 다른 프로레스가 점유하고 있는 자원을 무한정 대기하고 있는 상황을 말한다.
교착 상태가 발생학 위해서는 아래 4가지 조건이 필요하다
- 비선점: 다른 프로세스의 자원을 빼앗을 수 없다.
- 순환 대기: 두 개 이상의 프로세스가 공유 자원에 접근을 기다릴 때, 그 관계는 서로 순환적 구조이다.
- 점유 대기: 프로세스가 공유 자원을 이미 점유한 상태로 다른 프로세스의 공유 자원을 기다린다.
- 상호 배제: 공유 자원에 한 번에 한 프로세스만 접근이 가능하다.
가상화란?
단일 물리 하드웨어에서 여러 시뮬레이션 환경이나 전용 리소스를 생성할 수 있는 기술.
페이징(Paging)과 세그멘테이션(Segmentation)의 차이
페이징과 세그멘테이션은 프로세스를 메모리에 적재하는 방식이다.
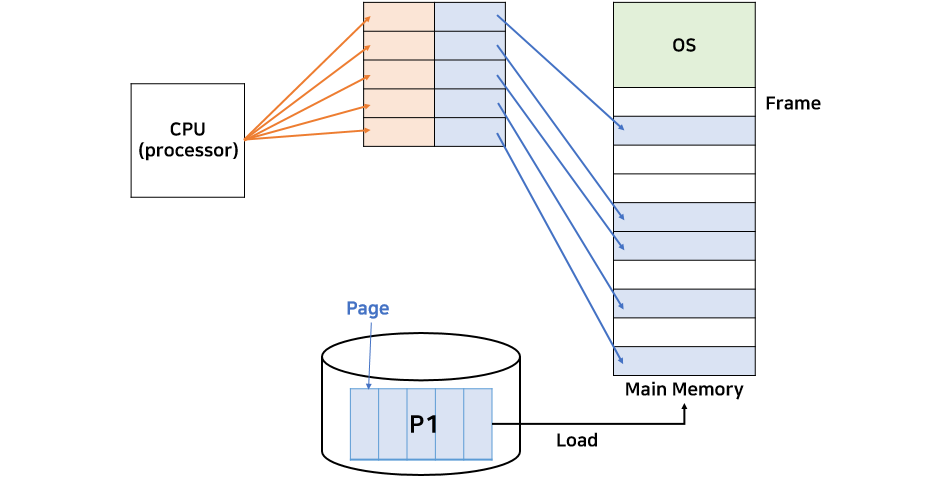
페이징은 프로세스의 주소 공간을 고정된 사이즈의 페이지 단위로 나누어 물리적 메모리에 불연속적으로 할당하는 방식이다.
메모리는 Frame이라는 고정크기로 분할되고, 프로세스는 Page라는 고정크기로 분할되며 Page와 Frame의 크기는 같다.
페이지와 프레임을 대응시키는 page mapping 과정이 필요하여 paging table을 생성해야 한다.
연속적이지 않은 공간도 활용할 수 있기 때문에 외부 단편화 문제 해결할 수 있다.
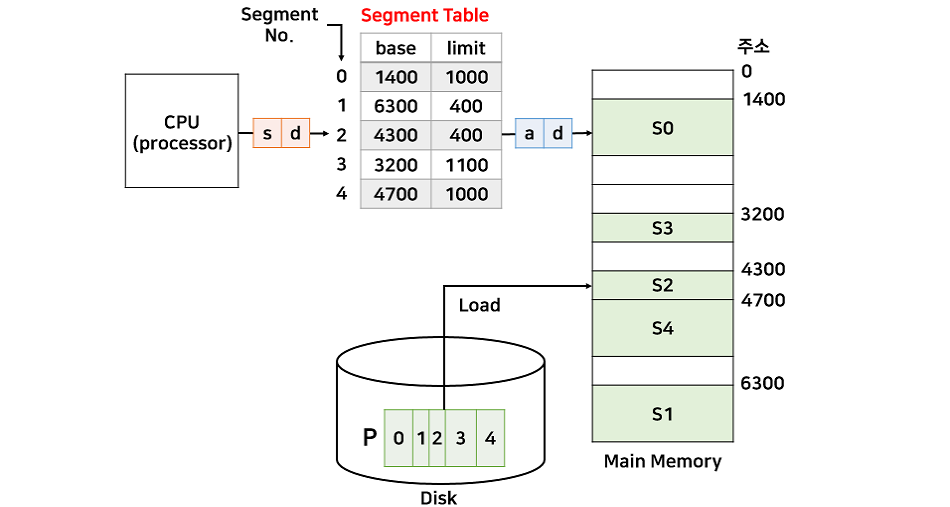
세그멘테이션은 프로세스를 서로 크기가 다른 논리적인 블록 단위인 세그먼트(Segment)로 분할하여 메모리에 할당하는 방식이다.
각 세그먼트를 연속적인 공간에 저장한다.
세그먼트들의 크기가 서로 다르기 때문에 프로세스가 메모리에 적재될 때 빈 공간을 찾아 할당하는 기법이며 페이징과 마찬가지로 mapping을 위한 segment table 필요하다.
프로세스가 필요한 메모리 공간만큼 메모리를 할당해 주기 때문에 내부 단편화 문제는 발생하지 않지만, 중간에 메모리를 해제하면 외부 단편화 문제가 발생한다.
데이터베이스
RDBMS와 NoSQL의 차이
RDBMS는 스키마에 맞춰 데이터를 관리하기 때문에 정합성을 보장할 수 있지만 시스템이 커질수록 성능이 저하된다.
NoSQL은 스키마 없이 Key-Value의 형태로 유연하게 데이터를 관리하지만 오히려 단점이 되기도 한다.
인덱스(Index)란?
데이터를 조회할 때 Full scan을 하지 않기 위한 자료구조이다.
보통 B+ tree구조로 인덱스를 생성한 컬럼의 데이터를 정렬한 별도의 테이블을 만든다. 최악의 경우에도 O(logN)의 성능을 보장한다.
하지만 Select를 제외한 모든 동작에 악영향을 주며 추가적인 저장 공간이 필요하다.
트랜잭션(Transaction)이란?
트랜잭션이란 일련의 작업들이 모두 처리되거나 모루 처리되지 않는 기능을 말한다.
트랜잭션을 보장하기 위한 성질을 ACID 원칙이라고 한다.
- 원자성(Atomicity): 작업이 모두 반영되던지 아니면 전혀 반영되지 않아야 한다.
- 일관성(Consistency): 실행이 완료되면 언제나 일관성 있는 상태를 유지해야 한다.
- 독립성(Isolation): 둘 이상 트랜잭션이 동시에 실행될 경우 서로의 연산에 끼어들 수 없다.
- 영속성(Durability): 완료된 결과는 영구적으로 반영되어야 한다.
트리거(Trigger)란?
특정 테이블에 어떤 이벤트가 발생했을 때 자동으로 동작하는 작업이다.
정규화(Normalization)이란?
테이블 설계에서 중복을 최소화하게 데이터를 구조화 하는 작업이다.
이상(anomaly) 있는 관계를 재구성하고 테이블간 관계를 잘 설정하기 위한 작업.
샤딩(Sharding)이란?
데이터를 여러 데이터베이스에 분할하여 저장하는 방법.
하나에 데이터베이스에 몰리는 부하를 분배할 수 있다.
옵티마이저(Optimizer)란?
SQL이 가장 효율적으로 처리될 수 있도록 최적의 처리 경로를 생성해 주는 데이터베이스의 핵심 엔진이다.
DB 트랜잭션 Isolation level
트랜잭션 격리 수준이란 여러 트랜잭션이 동시에 처리될 때, 특정 트랜잭션이 다른 트랜잭션에서 변경/조회할 수 있게 허용할지 여부를 결정하는 것이다.
SERIALIZABLE
SERIALIZABLE은 가장 엄격한 격리 수준으로 트랜잭션들을 순차적으로 진행시킨다.
여러 트랜잭션이 동시에 동일 레코드에 접근할 수 없으며, 데이터 부정합이 일어나지 않는다.
하지만 모든 트랜잭션이 순차적으로 처리되기 때문에 성능이 떨어진다.
SERIALIZABLE에서는 순수한 'SELECT' 작업에서도 대상 레코드에 락을 잡는다.
REPEATABLE READ
특정 레코드 조회 시 항상 같은 데이터를 응답하는 것을 보장하는 격리 수준이다.
일반적으로 RDBMS는 변경 이전의 레코드를 '언두 공간'에 백업한다. 그러면 변경 전/후 데이터가 모두 존재하기 때문에 동일한 레코드에 대해서 여러 버전의 데이터가 존재한다고 하여 이것을 MVCC(Multi-Version Concurrency control, 다중 버전 동시성 제어)라고 부른다. MVCC를 통해 롤백된 데이터를 복원하고, 서로 다른 트랜잭션 간의 접근을 세밀하게 제어할 수 있다.
각각의 트랜잭션은 순차 증가하는 고유한 트랜잭션 번호를 가지며, 백업 레코드에는 어느 트랜잭션에 의해 백업되었는지 트랜잭션 번호를 함께 저장한다.
REPEATABLE READ에서는 자신의 트랜잭션 번호를 참고하여 자신보다 먼저 실행된 트랜잭션의 데이터만 조회한다.
만약 테이블에 자신보다 이후에 실행된 트랜잭션의 데이터가 존재한다면 '언두 로그'에서 데이터를 조회한다.
REPEATABLE READ는 레코드가 추가되는 것을 막지 않기 때문에 트랜잭션이 끝나기 전에 다른 트랜잭션에 의해 추가된 레코드가 조회되는 팬텀 리드(Phantom Read)가 발생할 수 있지만 일반적인 조회에서는 MVCC를 통해 트랜잭션 번호를 참고하여 자신보다 나중에 실행된 트랜잭션의 데이터는 무시하여 팬텀 리드를 방지한다.
하지만 아래처럼 각각의 'SELECT FOR UPDATE' 사이에 다른 트랜잭션에서 데이터를 추가하는 경우에는 팬텀 리드가 발생한다.
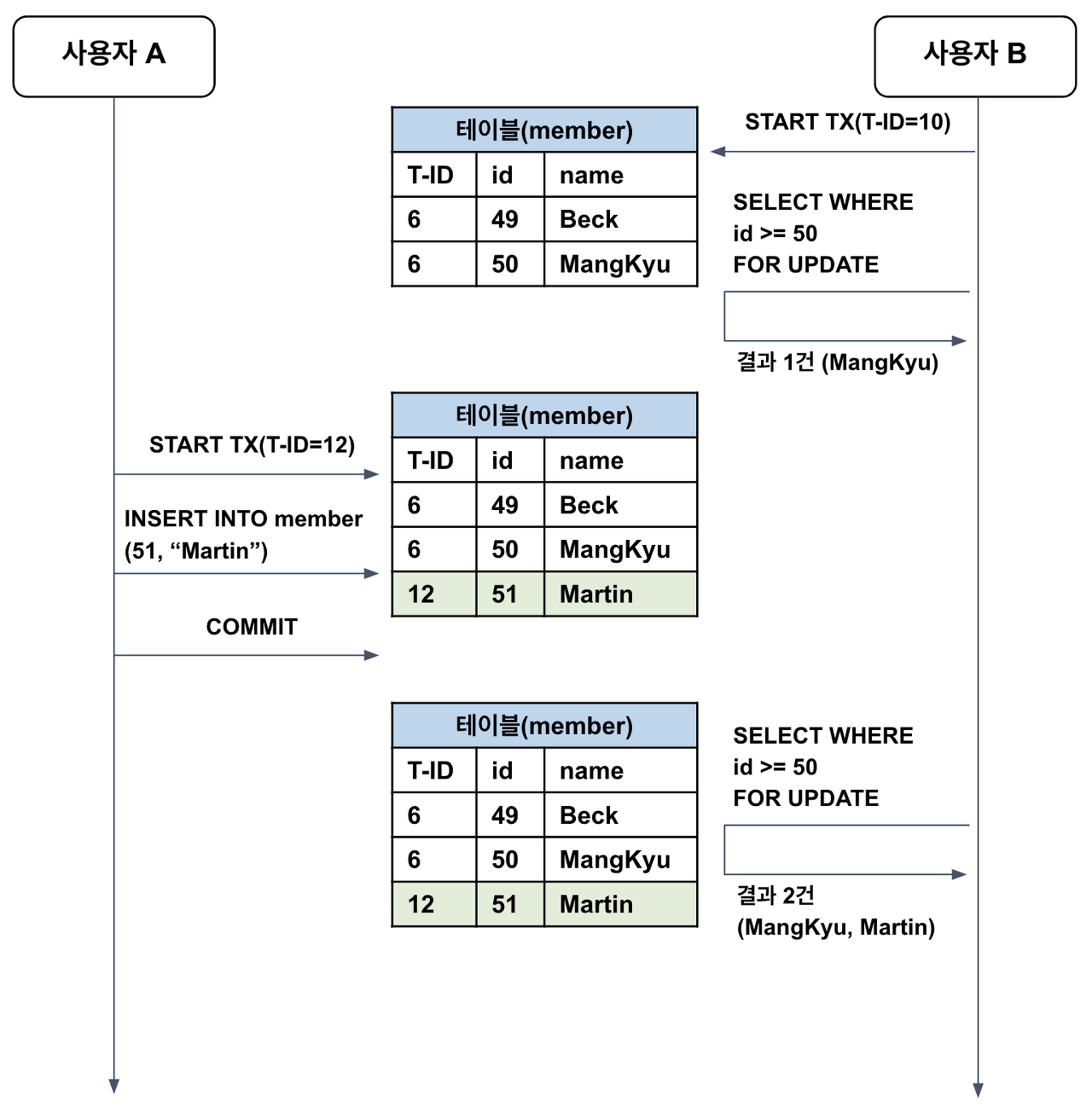
위와 같은 경우에는 두 번째 'SELECT FOR UPDATE'에서도 MVCC가 해결해 줄 것 같지만 안된다.
MVCC에서는 데이터를 테이블에 먼저 반영하고 언두 로그에 백업한다. 그리고 언두 로그는 락을 걸 수 없는 append only이기 때문에 'SELECT FOR UPDATE'에 락을 걸어도 언두 로그에는 다른 트랜잭션의 데이터가 계속해서 쌓인다.
만약 먼저 시작된 트랜잭션이 존재하여 작업을 하면 테이블에는 반영되고, 언두 로그에는 이전 트랜잭션의 데이터가 쌓인다. 그래서 DB에서는 'SELECT FOR UPDATE'나 'LOCK IN SHARE MODE'로 레코드를 조회하면 언두 영역의 데이터가 아니라 테이블의 레코드를 가져오게 되고, 이로 인해 Phaontom Read가 발생한다.
READ COMMITTED
READ COMMITTED은 커밋된 데이터만 접근할 수 있는 격리 수준이다.
READ COMMITTED는 커밋된 모든 데이터를 읽을 수 있기 때문에 Phantom Read와 더불어 조회할 때마다 동일한 데이터를 보장할 수 없는 Non-Repeatable Read(반복 읽기 불가능) 문제까지 발생한다.
READ UNCOMMITTED
READ UNCOMMINTTED는 커밋되지 않은 데이터까지 접근할 수 있는 격리 수준이다.
다른 트랜잭션에서 완료되지 않은 작업을 볼 수 있는 Dirty Read 문제가 발생할 수 있다.
Dirty Read는 데이터가 조회되었다가 사라지는 현상을 초래하여 시스템에 상당한 혼란을 준다.
참조: https://mangkyu.tistory.com/299
Spring
Spring 대비 Spring boot의 장점
Spring boot은 auto configuration기능으로 대부분의 설정을 자동으로 해주며 내장 Tomcat을 제공하기 때문에 별도의 서버 설정 없이 서버를 바로 띄울 수 있다.
Auto Configuration 이란?
Auto Configuration은 Spring boot와 연동되는 라이브러리 의존성을 추가해 주면 Bean설정과 생성을 자동으로 해주는 편의 기능이다.
Auto Configuration은 spring-boot-project의 하위 모듈인 'spring-boot-autoconfigure' 구현되어 있으며
하위에 jdbc, data, jackson 등등의 하위 디렉토리가 존재하고 AutoConfiguration 설정이 포함되어 있다.

참조: https://brunch.co.kr/@anonymdevoo/49
DI(Dependency Injection) 이란?
필요한 객체를 클래스 내부에서 직접 생성하는 것이 아닌 외부에서 주입받아서 사용하는 기법.
객체 간 결합도를 줄이고 코드 재사용성을 높일 수 있으며, 주입받는 대상이 변하더라도 해당 클래스의 구현을 수정하지 않아도 되는 장점이 있다.
IoC(Inversion of control) 이란?
객체에 대한 생성, 생명 주기 등의 제어를 개발자가 직접 하는 것이 아닌 프레임 워크에게 위임하는 것.
Spring에서는 IoC 컨테이너가 객체의 생성, 의존성 관리, 주입 등을 자동으로 해준다.
Bean을 등록하는 방법은?
@ComponentScan + @Component
Bean으로 등록하려는 클래스에 @Component 어노테이션을 붙여주고
@ComponentScan을 통해 @Component 어노테이션이 붙어있는 클래스들을 Bean으로 만드는 방법이다.
Spring boot을 사용해 서버를 만들 때 흔히 사용되는 @SpringBootApplication 어노테이션 내부에는 @ComponentScan이 포함되어 있고
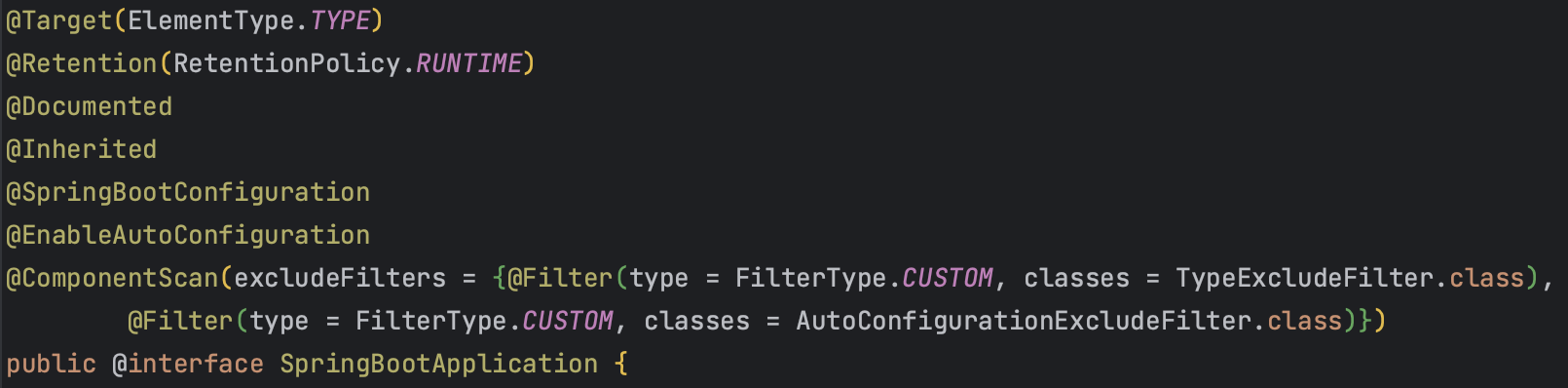
@Controller, @Service, @Repository 내부에 @Component 어노테이션을 포함되어 있다.

@Configuration + @Bean
클래스에 @Configuration을 추가하고 하위에 @Bean 어노테이션을 사용해 Bean을 추가하는 방법이다.
@Configuration은 Bean을 등록할 때 싱글톤이 되도록 보장해 주며 스프링 컨테이너에서 Bean이 관리될 수 있도록 한다.
@Configuration 내부 구현을 보면 @Component가 추가되어 있다. 즉 해당 클래스도 Bean으로 등록된다.

@Configuration + @Bean 방법으로 Bean을 등록하면 메서드의 이름이 Bean이름이 되기 때문에 중복되지 않도록 주의해야 한다.
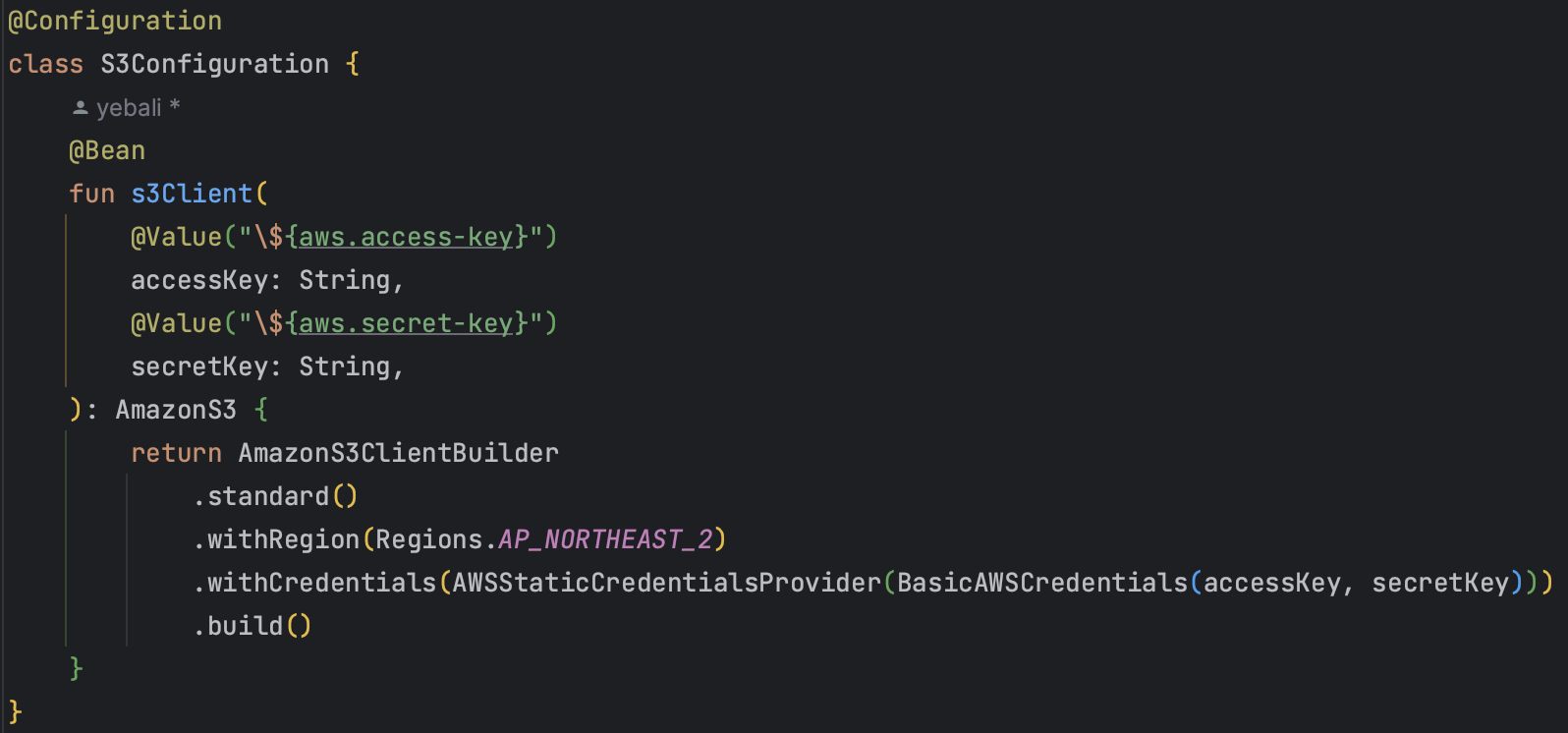
Bean을 주입받는 방법은?
- 생성자 주입: 클래스의 생성자를 통해 Bean을 주입받는 방법.
- 필드 주입: 클래스 내푸 필드에 @Autowired를 통해 주입받는 방법.
- 세터 주입: Setter를 통해 Bean을 주입받는 방법.
Spring AOP란?
핵심 기능과 부가 기능을 분리하여 자주 사용되는 부가 기능을 모듈화 하여 재사용할 수 있도록 지원하는 기능.
@Transaction 어노테이션은 AOP기능을 사용해 커넥션 풀 가져오기, 롤백, 커밋등과 관련된 코드를 재사용한다.
@Transaction에서 Rollback이 일어나는 Exception은?
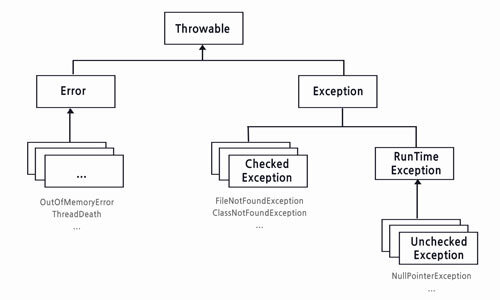

일반적으로 'RuntimeException'과 Error가 발생했을 때 Rollback이 일어난다.
만약 특정 Exception에서 Rollback을 하고 싶다면 @Transactional(rollbackFor='')을 사용하면 된다.
참조: https://wildeveloperetrain.tistory.com/218
N+1 문제란? 해결하는 방법
N+1 문제란 1번의 쿼리를 날렸을 때 의도하지 않은 N개의 쿼리가 추가적으로 발생하는 문제이다.
연관관계를 가진 엔티티를 조회할 때, 연결된 다른 엔티티(테이블)를 조회하지 않았을 때 발생한다.
위 문제는 연관관계를 가진 엔티티를 FetchJoin이나 @EntityGraph를 사용하여 함께 조회해 주면 해결된다.
참고로 FetchJoin을 사용할 경우 JPA가 제공하는 Paging API를 사용할 수 없다는 단점이 있다.
참조: https://yebali.tistory.com/81
Filter와 Interceptor의 차이
Filter
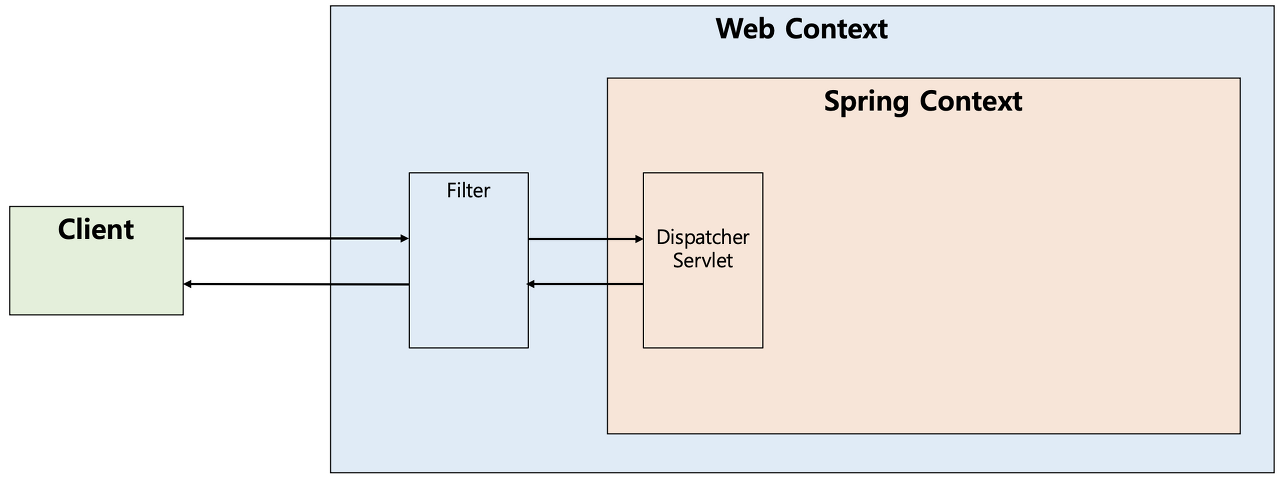
Filter란 클라이언트의 요청이 DisPatcher Servlet에 가기 전에 요청에 대한 부가 작업을 처리할 수 있는 기능이다.
ServletRequest/Response 객체를 조작할 수 있다.
원래는 Spring Context 밖에 존재하는 영역이기 때문에 Spring Bean들을 사용할 수 없지만, 요즘에는 서버를 띄울 때 내장 Tomcat을 사용하기 때문에 Filter에서도 Bean을 주입받아 사용할 수 있다.
Interceptor
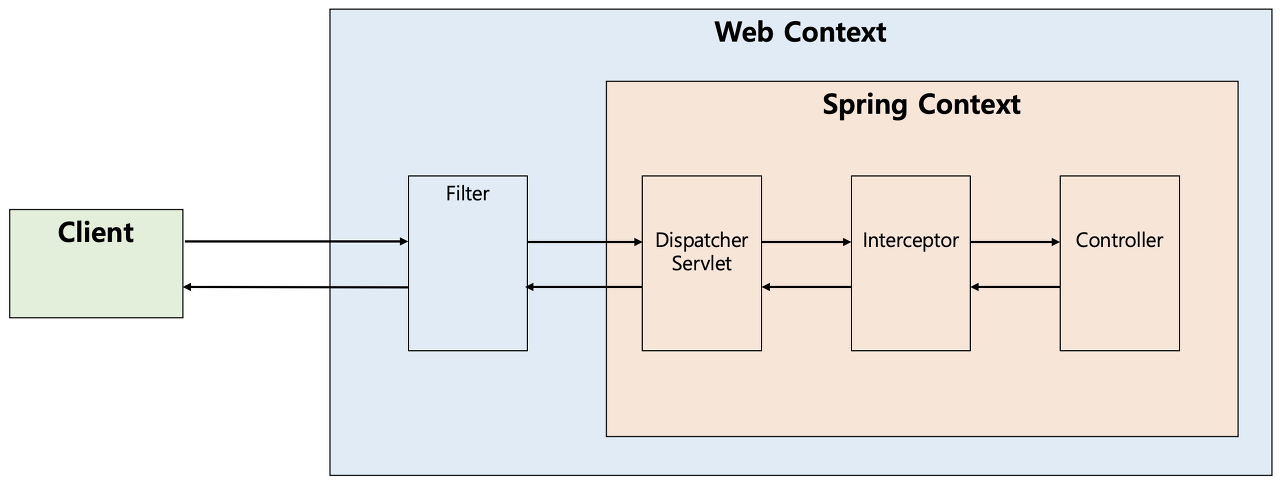
Interceptor란 클라이언트의 요청이 Dispatcher Servlet을 거쳐 Controller에 가기 전에 요청과 응답을 가공하는 기능이다.
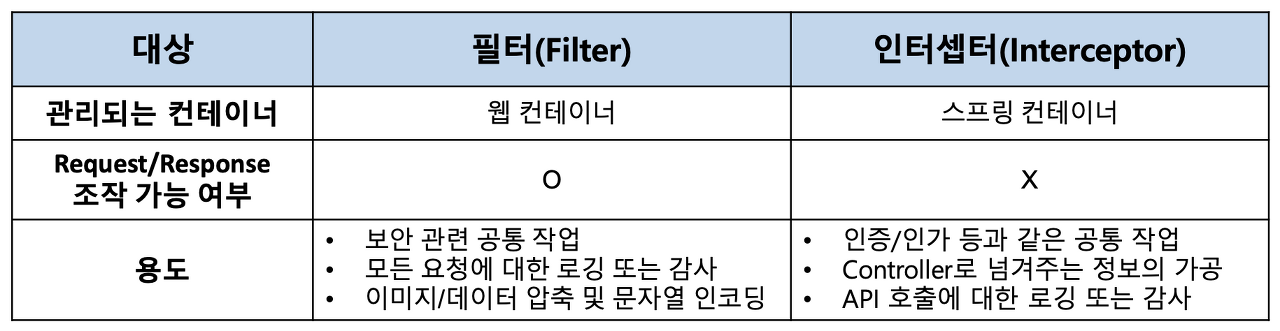
참조: https://yebali.tistory.com/53, https://mangkyu.tistory.com/221
@RequestBody, @ModelAttribute, @RequestParam의 차이점
@RequestBody
@RequestBody은 HTTP body를 MessageConverter를 통해 Object로 변환시켜 준다.
Reflection을 사용하기 때문에 별도의 Constructor, Setter가 없어도 동작한다
@ModelAttribute
@ModelAttirbute은 HTTP body나 request param으로 넘어오는 값들을 Object로 변환시켜 준다.
Constructor, Setter를 사용하여 동작한다.
@RequestParam
@RequestParam은 Query param으로 넘어오는 값들을 받을 때 사용한다.
참조: https://minchul-son.tistory.com/546
Spring Actuator란?
Spring Actuator은 Spring boot application의 상태 모니터링을 도와주는 도구이다.
Endpoint를 통해 서버의 상태나 각종 지표들을 수집할 수 있다.
Spring Bean은 싱글톤인데 멀티 스레드 환경에서 어떻게 thread-safe 한 이유는?
Spring의 Bean들은 thread-safe 하지 않다.
보통 개발자들이 Bean들을 상태를 가지지 않는 일종의 불변 객체로 만들기 때문에 괜찮은 것이다.
Java & Kotlin
Virtual Thread란?
Virtual Thread란 Java 21부터 지원하는 기능으로 전통적인 Java Thread에 더하여 새롭게 추가되는 일종의 경량 Thread이다.
OS의 Thread를 그대로 사용하지 않고 JVM 자체적으로 내부 스케줄링을 통해 사용할 수 있는 경량 Thread를 제공한다.
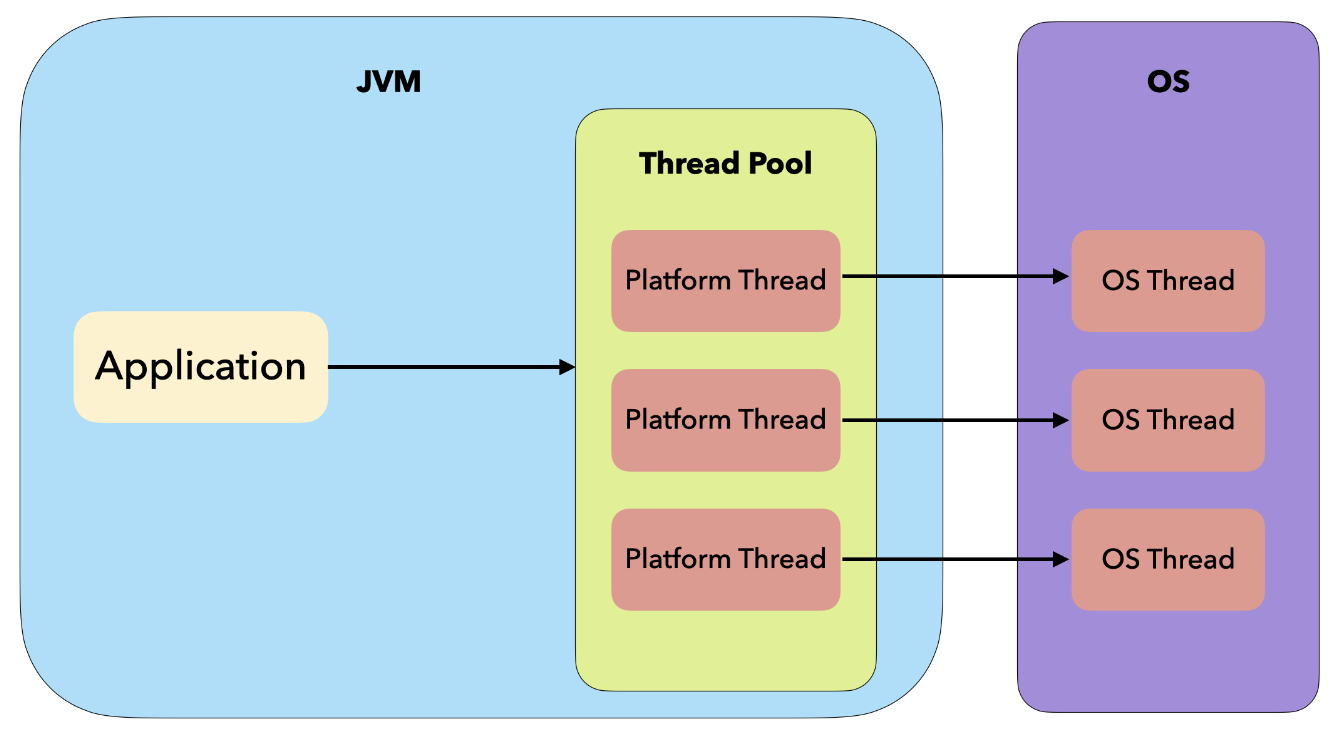
전통적인 구조에서는 코드가 실행되기 위해서 Thread Pool에 있는 Platform Thread(≒ OS Thread)를 사용한다.
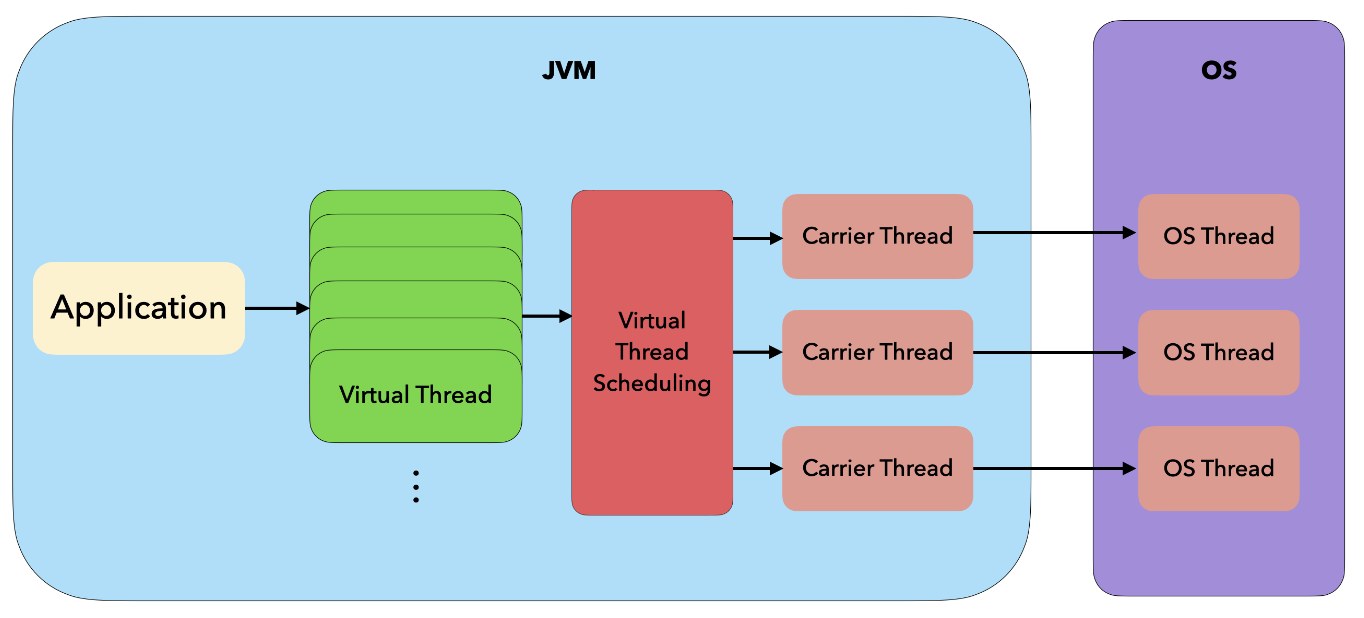
이에 반해 Virtual Thread는 JVM 자체적으로 Virtual Thread와 OS Thread를 연결하는 스케줄링을 한다.
전통적인 구조에서는 Blocking이 발생하면 Thread가 다른 일을 처리하지 않고 마냥 기다려야 했지만,
Virtual Thread에서는 Blocking이 발생하면 내부 스케줄링을 통해 Carrier Thread(≒ OS Thread)에 다른 작업을 할당해 처리한다.
따라서 Non-Blocking의 누리는 장점을 동일하게 가질 수 있다.
사용하는 자원
| Platform Thread | Virtual Thread | |
| Meta data size | 약 2kb | 200~300 B |
| Momory | 미리 할당된 Stack 사용 | Heap 사용 |
| context switcing time | 1~10us | ns or 1us 미만 |
참조: https://findstar.pe.kr/2023/04/17/java-virtual-threads-1/
JVM의 메모리 구조
JVM의 메모리는 애플리케이션이 실행될 때 사용하는 데이터들이 적재되는 영역이다.
크게 아래 5가지로 나뉜다.
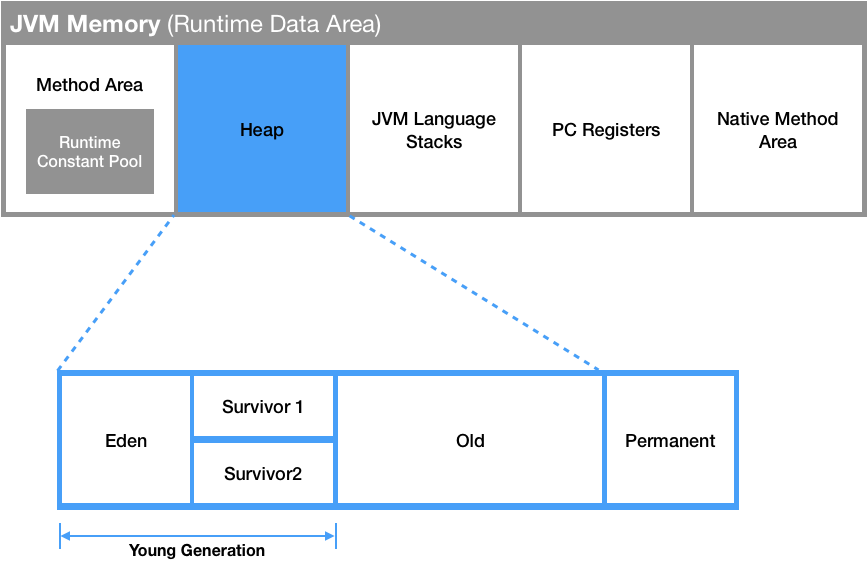
Method(Class) Area
모든 Thread가 공유하는 영역이다.
클래스, 인터페이스, 필드, Static 변수 등의 바이트 코드들이 적재된다.
Heap Area
모든 Thread가 공유하는 영역이다.
새롭게 생성된 객체들이 적재되는 영역으로 Method Area에 있는 클래스로부터 생성된 객체들만 적재가 가능하다.
Heap Area에 적재된 데이터들은 Galbage Collector에 의해 더 이상 참조되지 않을 때 메모리에서 제거된다.
Heap Area는 다시 아래 4가지 영역으로 나뉜다.
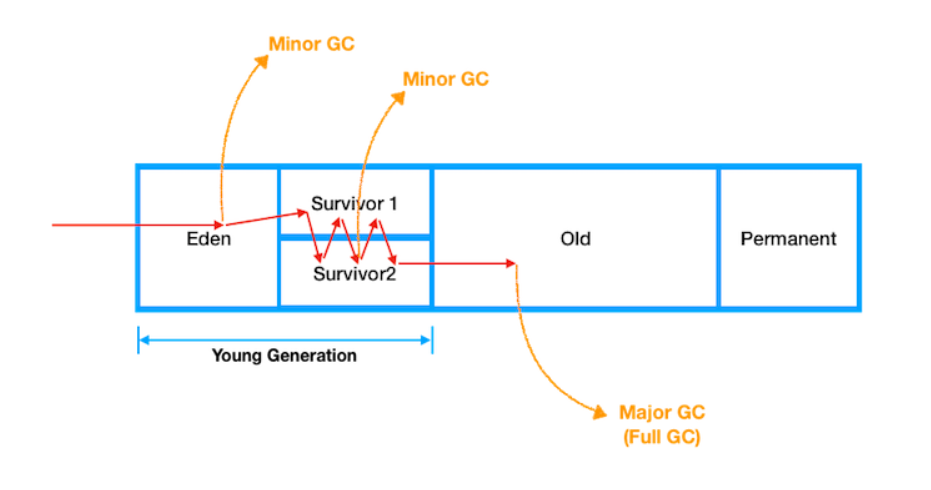
Eden, Survivor 영역을 묶어 Young Generation이라고 한다.
- Eden: 새롭게 생성된 객체들이 적재되는 영역. GC후 살아남은 객체들은 Survivor 영역으로 이동한다.
- Survivor1, 2: Minor GC후 Eden/Survivor 영역에서 살아남은 객체들이 적재되는 영역.
Survivor1, 2중 하나의 영역이 가득 차게 되면 GC과정에서 공간이 남아있는 Survivor으로 객체들이 이동하기 때문에
Survivor1, 2중 하나는 항상 비워진 상태로 유지된다. - Old: Survivor에서 오랫동안 살아남은 객체들이 이동하는 영역.
보통 Young 영역보다 크게 할당하기 때문에 해당 영역에 대한 GC가 덜 발생한다. - Permanent(Meta space): 클래스/메서드의 메타정보, Static 변수, 상수 등이 저장되는 영역.
Java8 이후부터 해당 영역은 Native 메모리 영역으로 JVM이 아닌 OS에서 관리되도록 변경되었다.
(Native Method Stack에 편입)
Stack Area
메서드를 호출할 때마다 각각의 스택 프레임이 저장되는 영역이다.
지역변수와 매개변수(Parameter)가 저장된다.
메서드 호출이 끝나면 해당 메서드의 스택 프레임은 삭제된다.
PC register
Thread가 시작될 때 생성되며, Thread가 실행할 명령정보가 저장되는 영역이다.
Native Method Stack
자바 외 언어로 작성된 네이티브 코드를 위한 메모리 영역이다.
참조: https://1-7171771.tistory.com/140
GC란?
GC(Garbage Collection)이란 JVM이 참조되지 않는 객체들을 메모리에서 자동으로 해제하는 기능을 말한다.
Mark and Sweep
Mark and Sweep이란 GC에서 사용되지 않는 객체를 찾아내고 제거하는 과정을 말한다.
아래 3가지 과정을 거친다.
- Mark: 그래프 순회를 통해 연결된 객체들을 찾아내며 참조되는 객체들을 마킹한다.
- Sweep: 참조되지 않는 객체들을 Heap에서 제거한다.
- Compact: Sweep후 분산된 객체들을 Heap의 시작 주소 쪽으로 모아 압축한다.
위 과정을 수행하기 위해 JVM은 GC관련 작업을 제외한 모든 프로그램의 실행(Thread)을 멈추는데,
이 현상을 STW(Stop The World)라고 한다.
GC는 발생하는 영역에 따라 Minor GC, Major GC로 나뉜다.
Minor GC
Young Generation(Eden, Survivor) 영역에 대한 GC이다.
Young Gerneration은 Old Gerneration에 비해 상대적으로 작은 메모리 공간을 갖기 때문에 시간이 적게 걸린다.
Major GC
Old 영역에 대한 GC이다. Full GC라고도 불리며 메모리 공간이 크기 때문에 Minor GC에 비해 10배 이상의 시간을 사용한다.
그렇기 때문에 STW 시간이 길어져 이 시간을 줄이기 위해 알고리즘을 개선하는 등의 GC 튜닝을 한다.
G1 GC란?
CMS GC를 대체하기 위한 GC로 Java 9 이상 버전에서 기본 GC이다.
기존 GC알고리즘과 다르게 Heap영역에서 Young, Old 영역을 나누어 사용하지 않고
전체 Heap영역을 'Region'이라는 영역으로 분할하여 Eden, Survivor, Old 영역을 동적으로 할당한다.
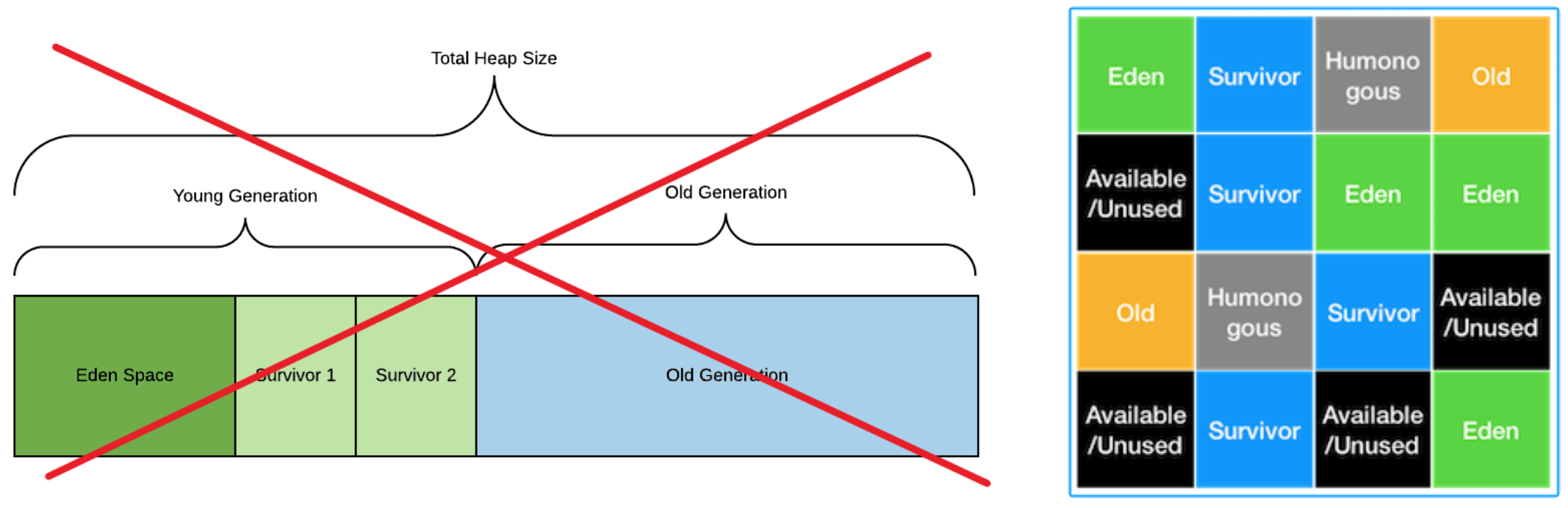
GC가 발생할 때 모든 메모리 영역을 탐색하지 않고 메모리가 많이 차있는 Region만 GC를 진행한다.
메모리를 Region으로 나누어 관리하기 때문에, 메모리가 너무 작은 경우 성능상 좋지 않다.
Reflection이란?
Reflection은 구체적인 클래스 타입을 알지 못하더라도 그 클래스의 메서드, 타입, 변수들에 접근할 수 있도록 해주는 자바 API이다.
Reflection을 사용하면 Runtime에 동적으로 특정 클래스의 정보(생성자, 필드, 메서드 등)를 알고 사용할 수 있다.
Relfection은 Spring의 DI, Hibernate, Junit 등 다양한 곳에 사용된다.
Collection이란?
Collection은 다수의 데이터를 효과적으로 관리할 수 있는 표준화된 방법을 제공하는 클래스의 집합니다.
Java, Kotlin에서는 대표적으로 List, Set, Map이 있다.
Servlet이란?
클라이언트의 요청을 처리하고 결과를 반환하는 Java WEB 프로그래밍 기술.
HTTP 요청를 받으면 HttpServletRequest, HttpServletResponse 객체를 만들고 요청에 맞는 Servlet을 찾아 요청을 처리한다.
Coroutine(코루틴)이란?
비선점적 멀티태스킹을 위해 서브 루틴을 일반화한 컴퓨터 프로그램 구성요소이다.
코드의 실행에 있어 중단과 재개를 자유롭게 하여 비동기 작업이나 동시성 프로그래밍을 지원한다.
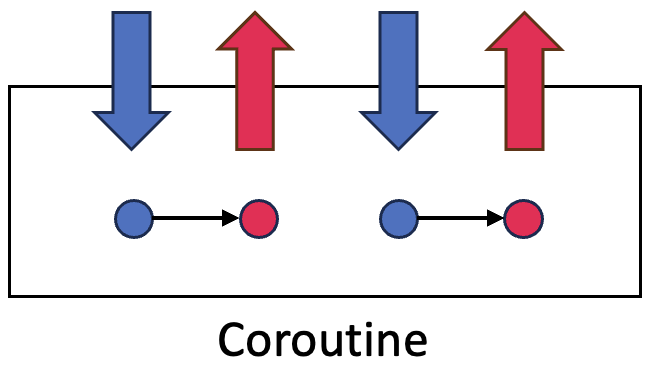
코루틴은 동시성은 제공하지만 병렬성은 제공하지 않으며
하나의 Thread 내에서 코루틴 간 관계 정의를 통해 중단/재개하기 때문에 Context Switching 비용이 발생하지 않는다.
Thread는 프로세서 내에서 실행되는 여러 작업의 흐름이며,
코루틴은 Thread 내에서 작업 단위를 나누어 동시성을 제공하며 동작하는 것이다.
'Backend Common' 카테고리의 다른 글
| k8s 환경에서 pinpoint 적용하기 (feat. NCP) (1) | 2023.12.31 |
|---|---|
| Sync/Async, Blocking/Non-Blocking (0) | 2023.10.09 |
| docker-compose (0) | 2023.07.09 |
| 분산락과 Redisson (0) | 2023.05.08 |
| [Socket] Socket이란? (0) | 2023.01.17 |


